해당 내용은 Datacamp의 Data engineering track을 정리했습니다.
3. Introduction to data engineering의 chapter 4에 대한 내용입니다.
# 1. Course ratings
DataCamp의 학생은 한 장을 완료한 후 평가할 수 있습니다. 이 챕터 등급을 집계하여 사람들이 특정 코스를 어떻게 평가하는지 추정할 수 있습니다. 이러한 종류의 등급 데이터는 추천 시스템에서 사용하기에 적합합니다.
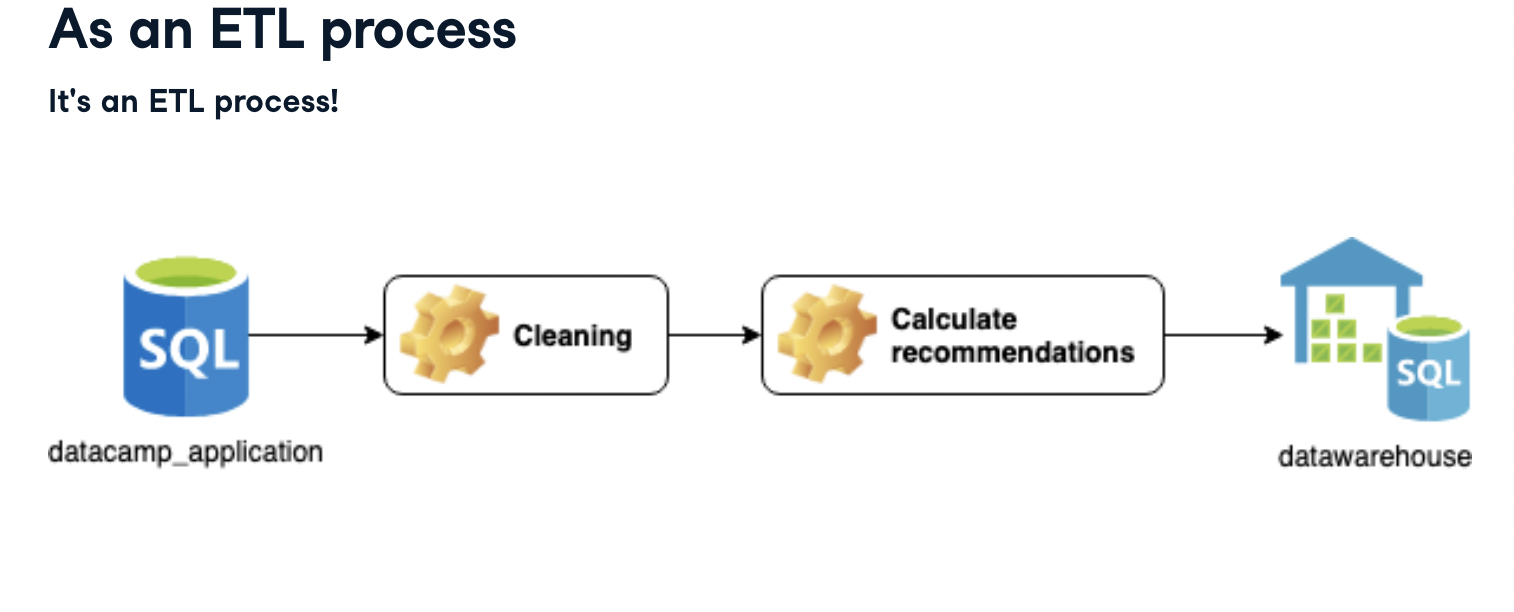
추천시스템에 평가 데이터를 사용하기 위해서는, 저장된 평가 데이터들을 추출(Extract)하고, 변환(Transform)한후, 데이터 베이스에 저장(Load)하는 일련의 과정이 필요합니다.
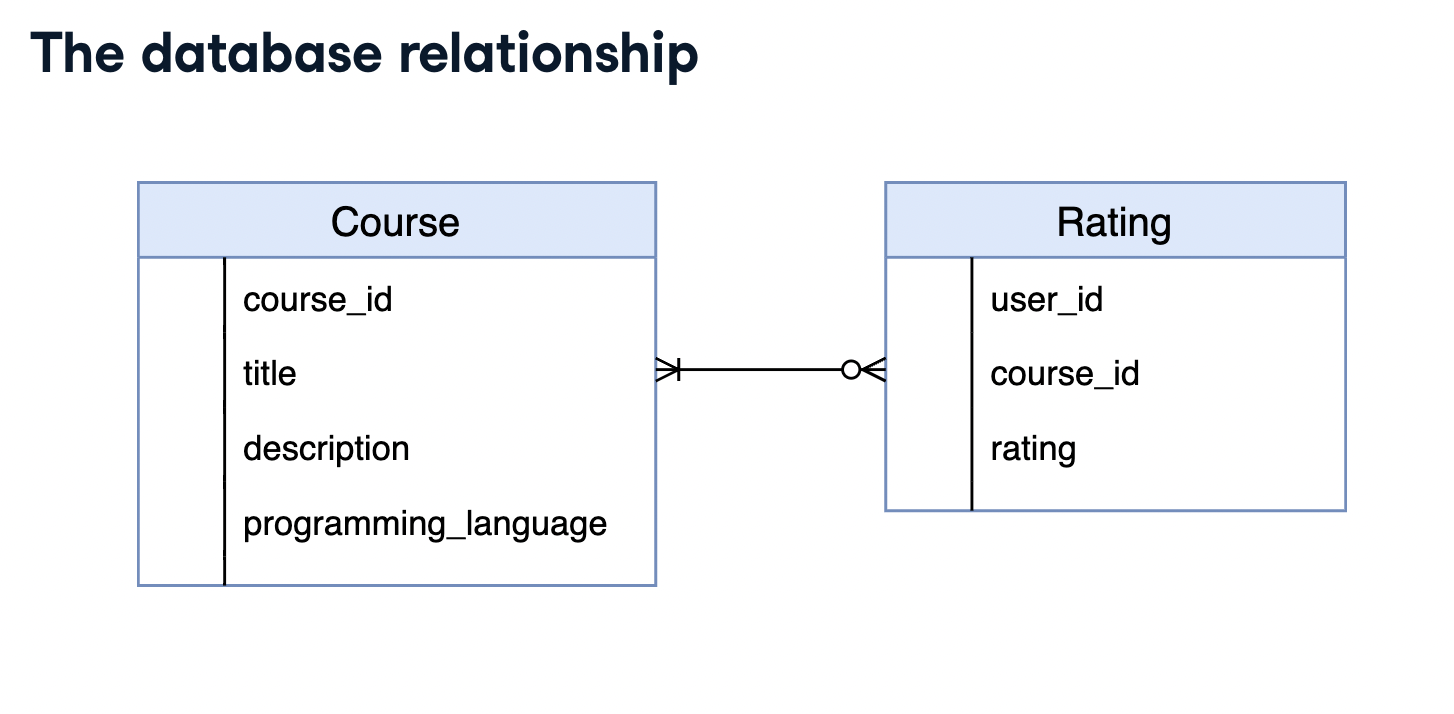
이 챕터에서는 Course와 Rating 두 개의 테이블을 이용할 것입니다. Rating의 course_id는 외래키로 Course 테이블에서 받아오게 됩니다.
## 1.1 Exploring the schema

## 1.2 Querying the table
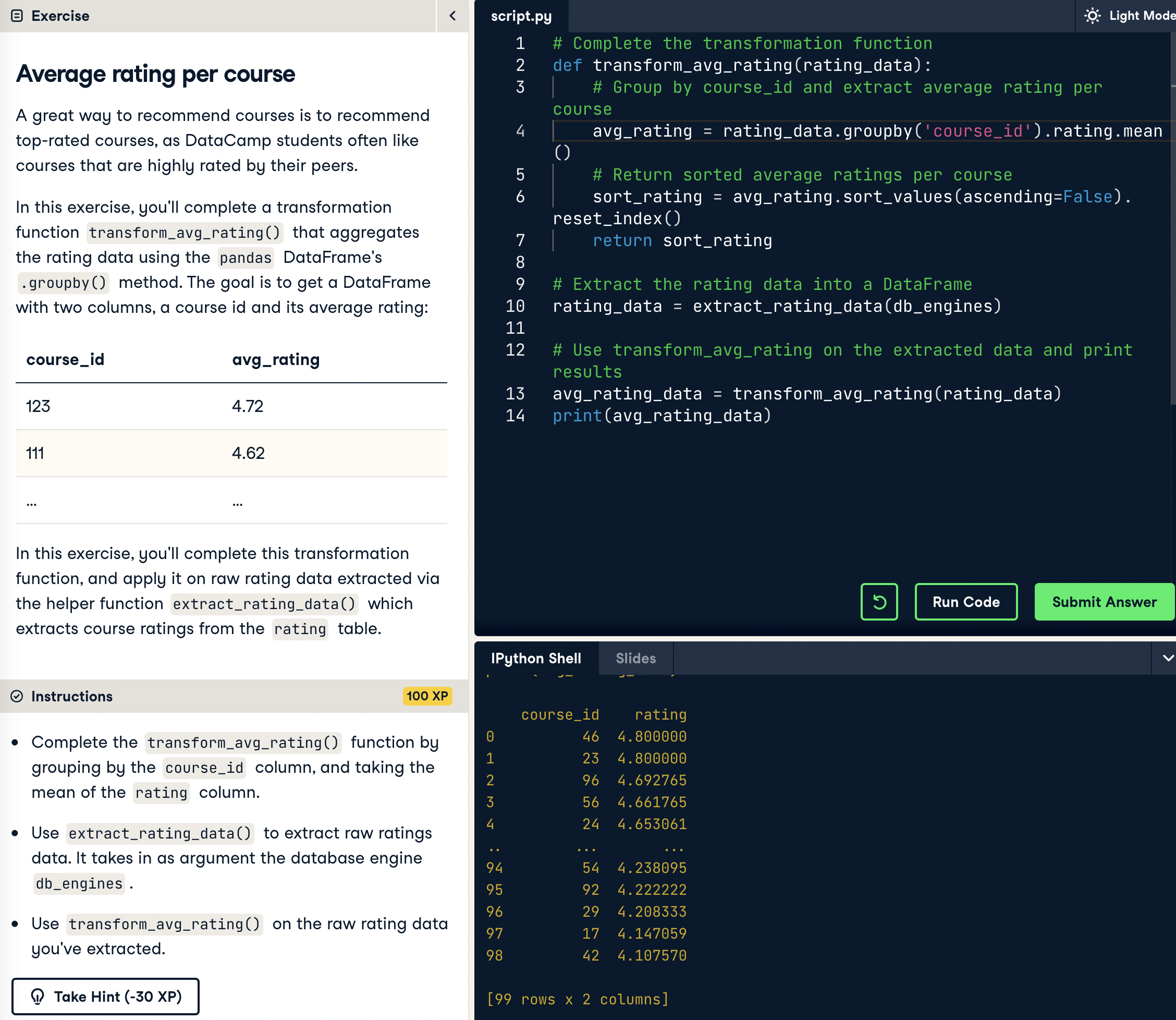
## 1.3 Average rating per course
# 2. From ratings to recommendations
위에서는 Raw 평가 테이블에서 데이터를 추출하고 변환하였습니다. 이제 이 변환된 데이터를 가지고 추천 시스템을 만들어 볼 차례입니다.
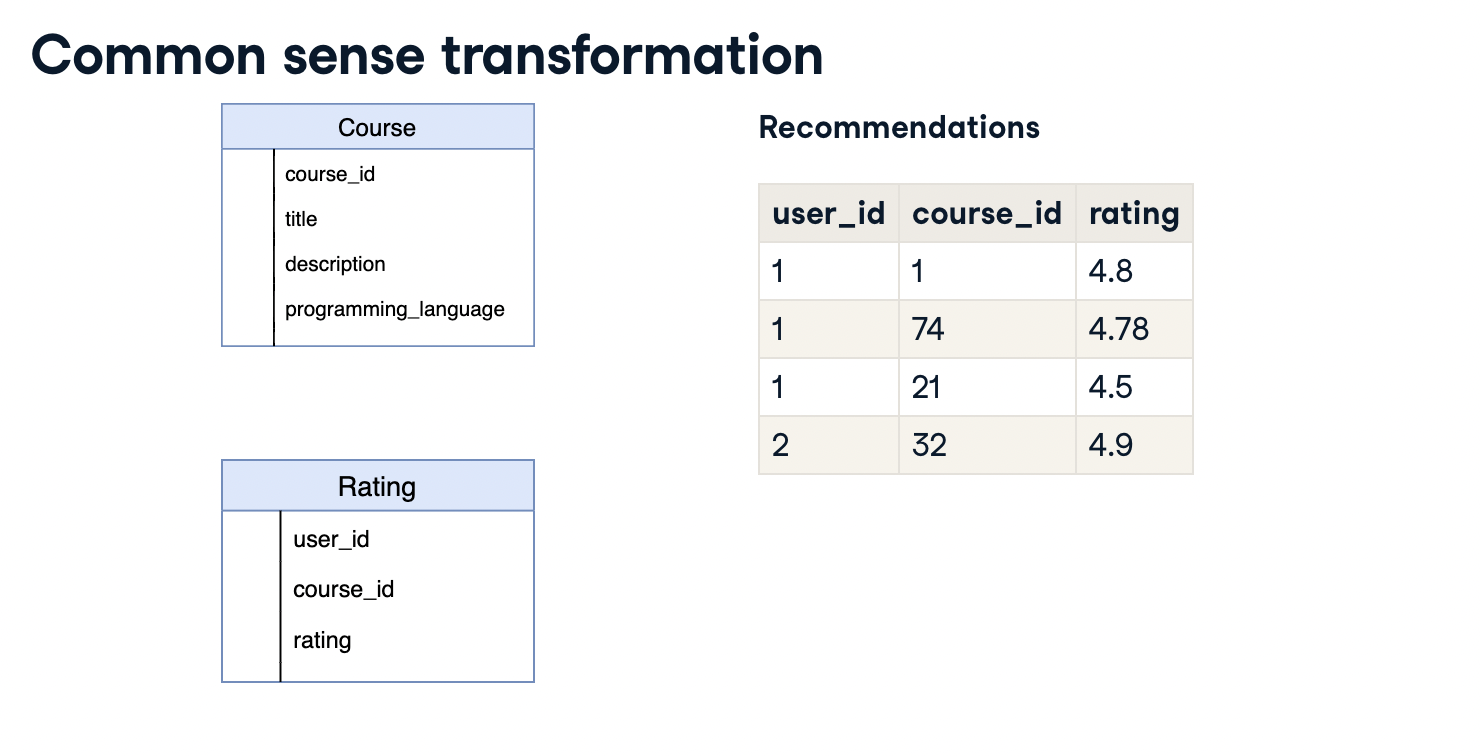
목표로하는 추천시스템의 테이블 형태는 위와 같습니다. Course와 Rating 테이블에서 추출한 데이터를 사용하여, 유저별로 각 강의마다 평가점수를 예측해서, Top3의 강의를 추천해 주는 것입니다.
해당 추천시스템을 만드는 과정은 Matrix factorization이라는 추천시스템 알고리즘 모델을 사용할 것입니다.
고려할점
- 첫번째로 고려할 것은 높은 평점을 가진 강의를 추천하는 것입니다. 이전까지 우리는 각 코스 ID에 대한 평균 코스 평점을 도출해냈습니다. 이 과정을 연계해서 사용할 것입니다.
- 두번째로 고려할 것은 사용자의 관심을 끄는 프로그래밍 언어로된 과정을 추천할 것입니다. 사용자가 평가한 강의 중 가장 높은 비중을 차지하는 언어를 추천해 줄 것입니다.
- 세번째로 사용자가 아직 평가하지 않은 강의만 추천할 것입니다. 즉 Rating 테이블에 user_id와 course_id의 조합이 있으면 안된다는 것입니다.
생성할 추천시스템의 규칙
1. 강의 추천수가 높은 강의들로 추천을 합니다.
2. 사용자가 평가하지 않은 강의들로 추천을 합니다.
3. 가장 높은 등급 3개의 코스를 추천합니다.
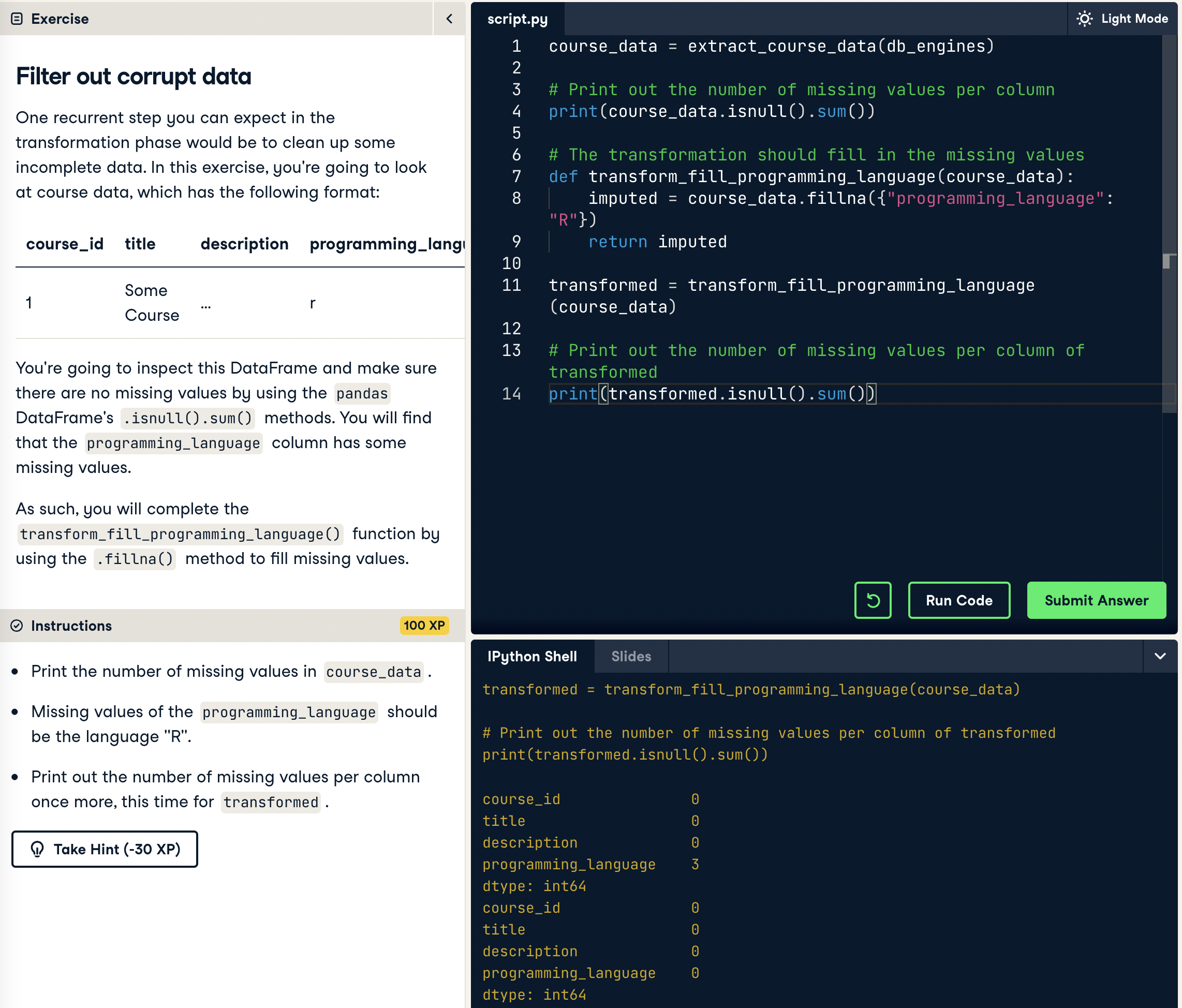
## 2.1 Filter out corrupt data
## 2.2 Using the recommender transformation
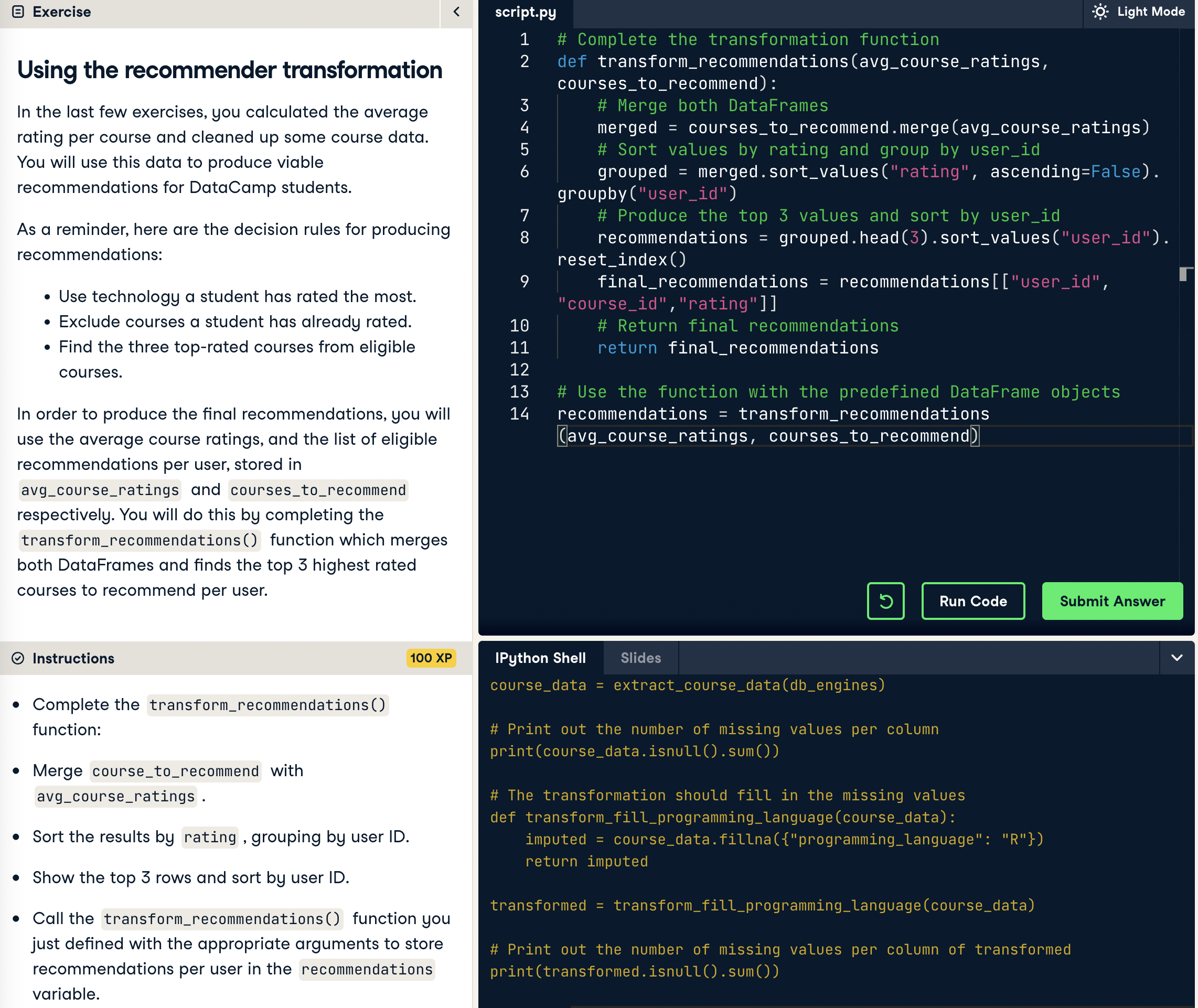
이렇게 추천시스템이 만들어진다... 해당 과정은 추천시스템 알고리즘 교육과정이 아니기 때문에 Matrix factorization 등의 과정은 생략되어있다.
# 3. Scheduling daily jobs

이제 데이터를 Postgres 테이블에 로드하고, Airflow를 통해 테이블을 최신화하는 일련의 과정을 해볼 것입니다.
추천테이블을 Sql로 만들어 load해야 합니다.
recommendations.to_sql(
"recommendations",
db_engine,
if_exists="append",
)The etl() function
def etl(db_engines):
# Extract the data
courses = extract_course_data(db_engines)
rating = extract_rating_data(db_engines)
# Clean up courses data
courses = transtorm_fill_programming_language(courses)
# Get the average course ratings
avg_course_rating = transform_avg_rating(rating)
# Get eligible user and course id pairs
courses_to_recommend = transform_courses_to_recommend(
rating,
courses,
)
# Calculate the recommendations
recommendations = transform_recommendations(
avg_course_rating,
courses_to_recommend,
)
# Load the recommendations into the database
load_to_dwh(recommendations, db_engine))Creating the DAG
from airflow.models import DAG
from airflow.operators.python_operator import PythonOperator
# 매일 0시에 실행
dag = DAG(dag_id="recommendations",
scheduled_interval="0 0 * * *")
task_recommendations = PythonOperator(
task_id="recommendations_task",
python_callable=etl,
)## 3.1 The target table

if_exists="replace"에서 조금 tricky한 문제
## 3.2 Defining the DAG

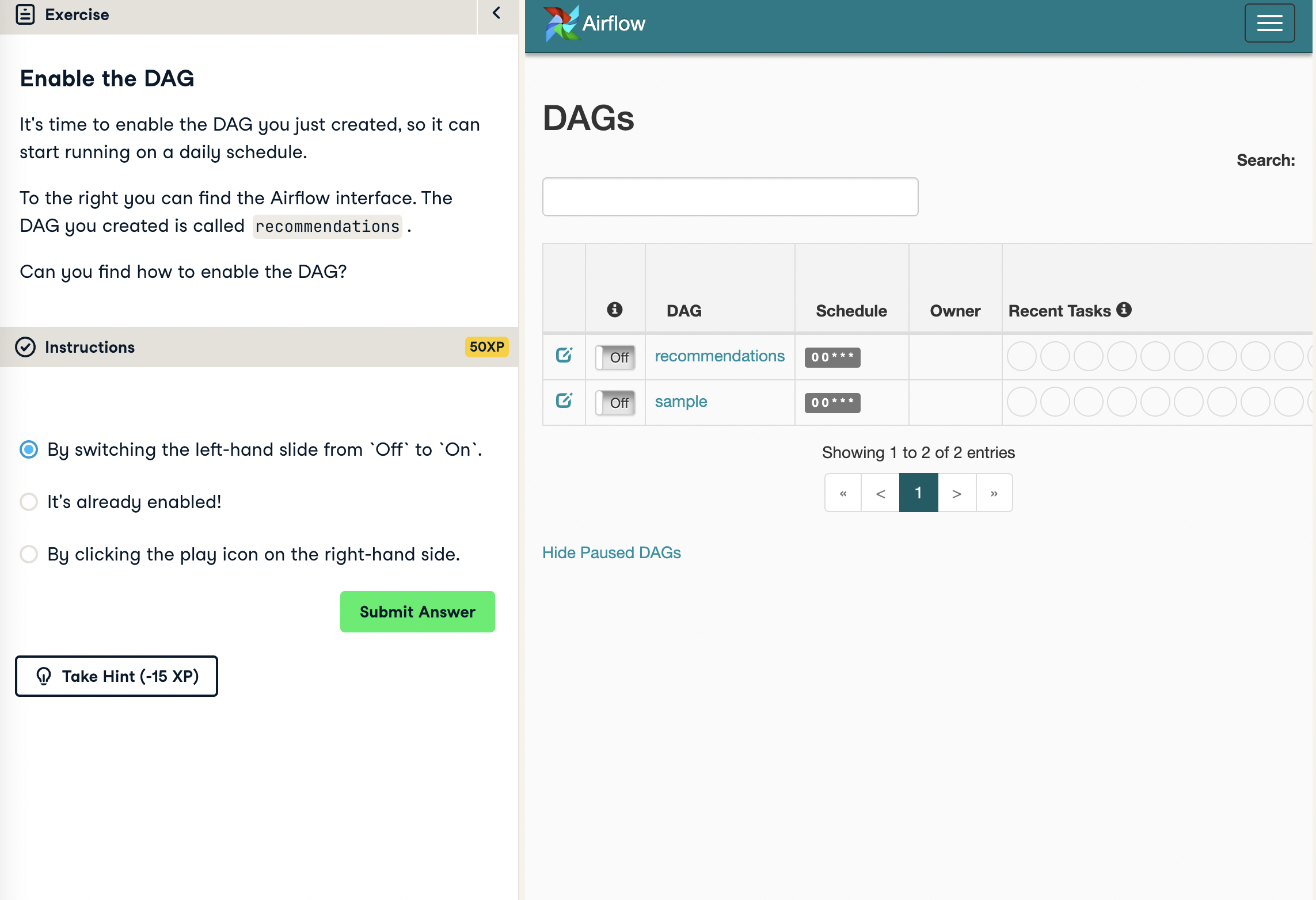
## 3.3 Enable the DAG
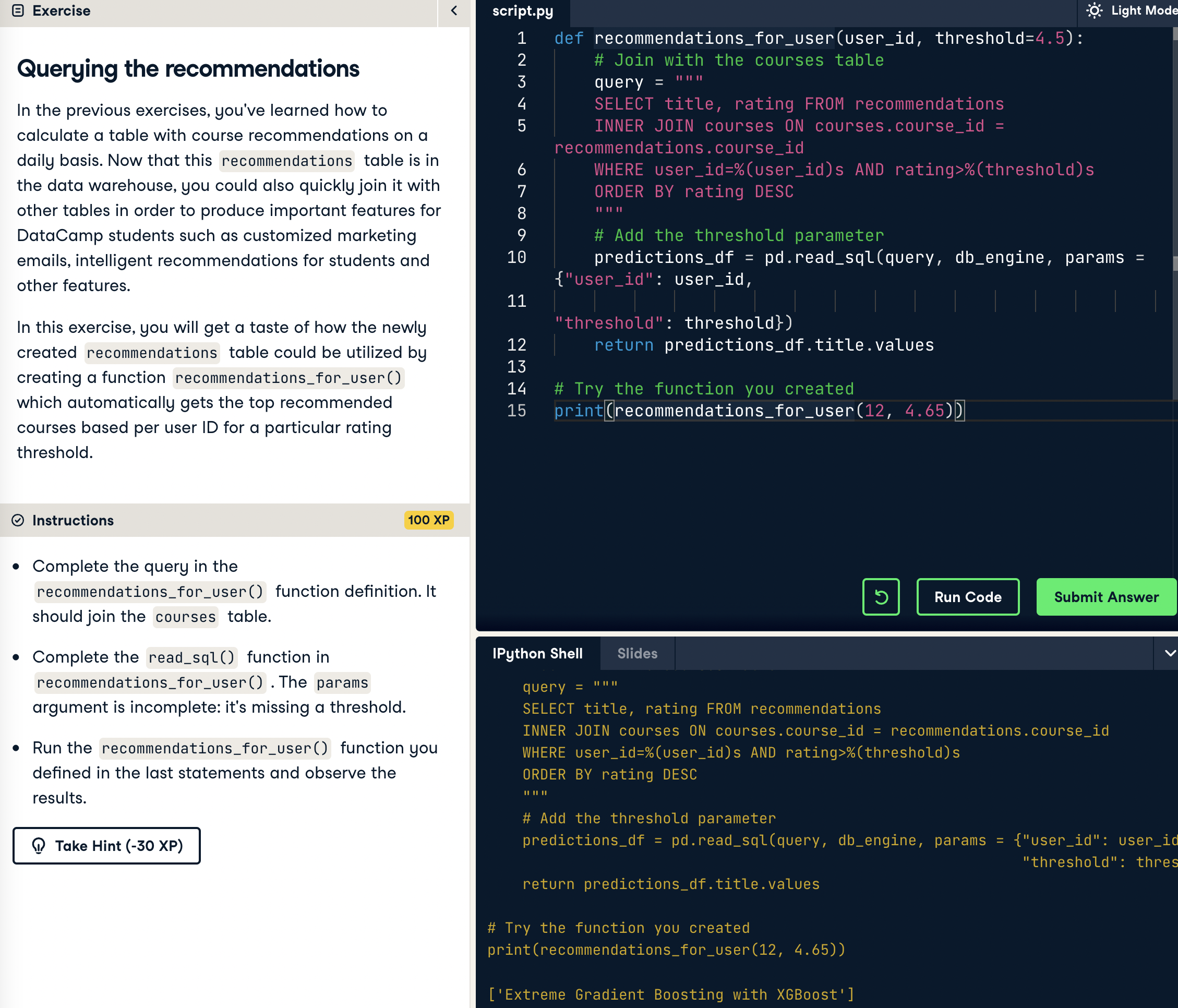
## 3.4 Querying the recommendations
'IT > 가짜연구소 스터디' 카테고리의 다른 글
| [DA] 4-4. Importing JSON Data and Working with APIs (0) | 2022.09.13 |
|---|---|
| [DA] 4-3. Importing Data from Databases (0) | 2022.09.13 |
| [DA]4-2. Importing Data From Excel Files (0) | 2022.09.13 |
| [DA] 4-1. Importing Data from Flat Files (0) | 2022.09.12 |